On the 80,000 Hours podcast, Rohin Shah calls today’s transformers wide but shallow — lots of parallel work per forward pass, but few sequential steps; deeper serial reasoning has to spill into the chain of thought, as tokens you can read. He and colleagues (Brown-Cohen, Lindner & Shah, 2026) formalise the limit as opaque serial depth: the longest computation a network can do without interpretable intermediate steps like chain of thought.
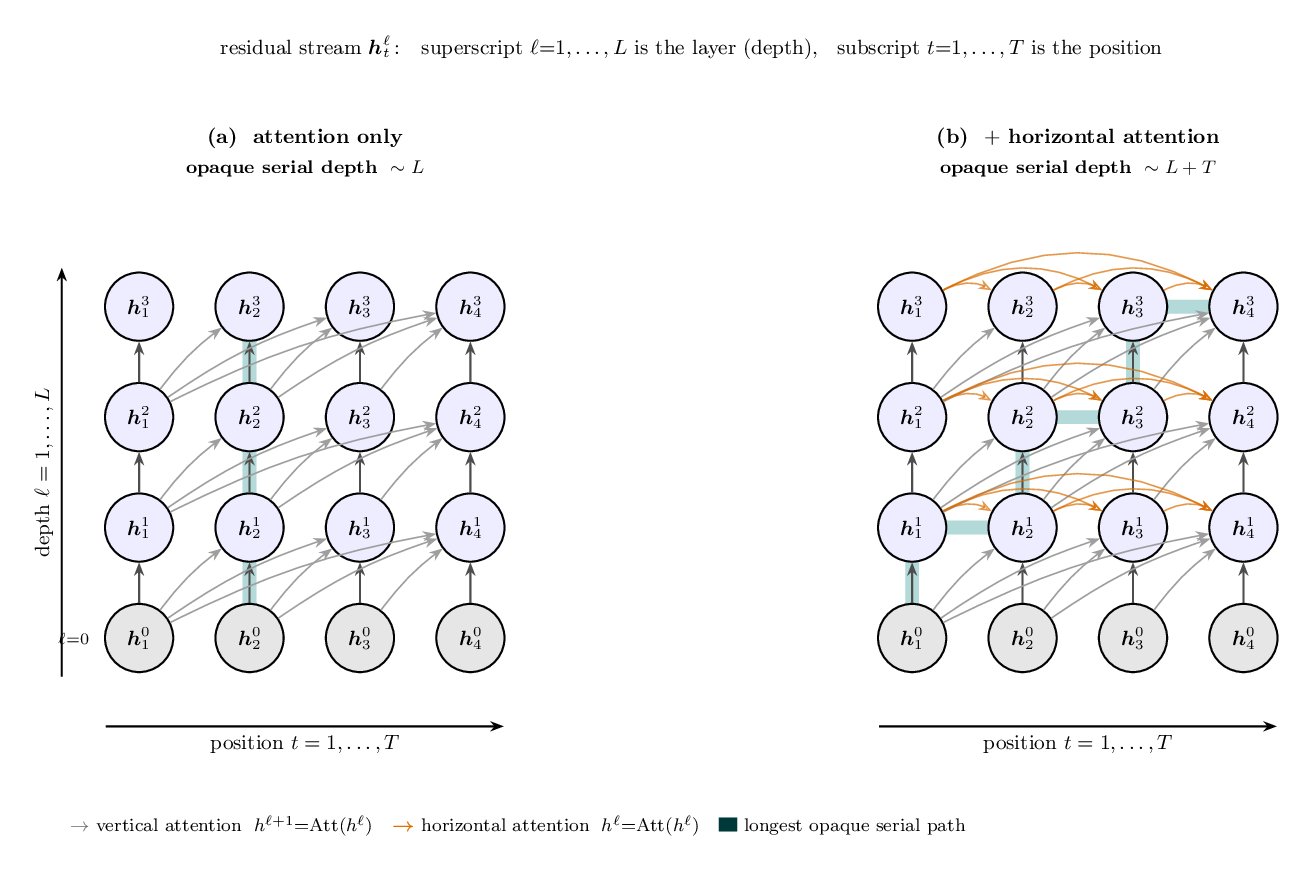
Take one causal-attention block $\mathrm{Att}$ (defined below). Stacking it the usual, vertical way, $h^{\ell+1}=\mathrm{Att}(h^{\ell})$, only ever reads a finished layer, so all positions run in parallel and depth is the lone serial axis: $\sim L$. A horizontal attention $h^{\ell}=\mathrm{Att}(h^{\ell})$ — same layer on both sides — reads the layer being written, so it resolves left-to-right across positions, and the longest dependency path now threads up $L$ layers and across $T$ positions: $\sim L+T$ (the staircase above).
One causal-attention block $\mathrm{Att}$: at query position $t$ it sums over the key positions $t'\le t$ — the arcs in the figure — with $\boldsymbol q_t=W_Q\boldsymbol h_t$, $\boldsymbol k_{t'}=W_K\boldsymbol h_{t'}$, $\boldsymbol v_{t'}=W_V\boldsymbol h_{t'}$:
$$ \begin{aligned} \mathrm{Att}(\boldsymbol h)_t &= \sum_{t'\le t}\big(W_Q\boldsymbol h_t \cdot W_K\boldsymbol h_{t'}\big)\,W_V\boldsymbol h_{t'} \\ &= \sum_{t'\le t}\big(\boldsymbol q_t\cdot \boldsymbol k_{t'}\big)\,\boldsymbol v_{t'} \end{aligned} $$(scores softmax-normalised over $t'$). Unrolling the layer loop — the only difference is the extra horizontal lines on the right:
(a) attention only
h1 = attn(h0) # h^1 = Att(h^0)
h2 = attn(h1) # h^2 = Att(h^1)
h3 = attn(h2) # h^3 = Att(h^2)
# ... L layers depth ~ L
(b) + horizontal attention
h1 = attn(h0) # h^1 = Att(h^0)
h1 = attn(h1) # h^1 = Att(h^1) <- horizontal
h2 = attn(h1) # h^2 = Att(h^1)
h2 = attn(h2) # h^2 = Att(h^2) <- horizontal
h3 = attn(h2) # h^3 = Att(h^2)
h3 = attn(h3) # h^3 = Att(h^3) <- horizontal
# ... depth ~ L + T
The horizontal lines feed h straight back into the same block — $h^{\ell}$ on both
sides — so, unlike the vertical lines, they can’t be parallelised over positions: vertical
$\mathrm{Att}$ moves $\ell\!\to\!\ell\!+\!1$ and parallelises, horizontal $\mathrm{Att}$
stays at $\ell$ and serialises (the blank lines on the left mark exactly what (b) adds).
Bigger opaque serial depth means more reasoning hidden inside one forward pass instead of written down — which is why it’s floated as an architecture-level safety metric (the paper bounds it for Gemma 3, and finds Mixture-of-Experts models lower than dense ones).
Rohin Shah — 80,000 Hours · arXiv:2603.09786 · figure PDF / TikZ. The horizontal variant is a simplified illustration; the paper derives $L+T$ for replacing attention with RNN blocks.